SSD(Single Shot MultiBox Detector)のほうが有名かもしれないが、当記事では比較的簡単に扱い始めることができるYOLOを取り上げる。
kerasでSSDを使おうと見てみると、keras2.0では。。。最終テストはkeras1.2.2、Tensorflow1.0.0?????
そして更新も2年前。
https://github.com/rykov8/ssd_keras
YOLOv3はすごい
You only look once でYOLOと略す。名前の通りで、一度見るだけですごいとわかる。
今はYOLOはヴァージョン3、すなわちYOLOv3である。
1つのニューラルネットワークをフルイメージに適用するという従来とは全く違うアプローチをしている。
簡単に言えば、今までのものより正確に早く物体検出・物体検知をしてくれる便利なもの。導入も簡単。
ディープラーニングで自分が一からモデルを構築しなくても、YOLOは初期装備でかなり使える。
画像はもちろん、Webカメラなどとも連動できる。リアルタイムに物体検出が可能ということ。
YOLOの導入、インストール、使い方
公式ページのままにやれば問題ないが、もちろん記事にするのだから補足的に付け足す。
まずはYOLOを動かしたいディレクトリに移動し、ダウンロードしてくる。git cloneが使える。
Macの人ならターミナルを開いて、以下のコマンドを打ち込めば良い。
無事にgit cloneできたら、darknetディレクトリに移動する。(cdはchange directory)
そして、makeコマンドでコンパイルする。C言語を利用しているから。
特に難しく考えず、darknetディレクトリに移動したらmakeと打てばよい。
丁寧すぎるかもしれないが、たとえばMacの書類(Documents)に自分でpython_codeというフォルダを作っていて、そこにYOLOをインストールしたいとする。
makeコマンドを入力する段階では以下のような感じになっているはず。
[UserName] ~/Documents/python_code/darknet$ make
次に、重みのファイルをダウンロードする。
そのまま以下のコマンドを打ち込んで、yolov3.weightsをとってくる。
237MBあるが、気長に待とう。
それでは、早速使ってみる。
darknetフォルダにはdataフォルダがあり、その中にサンプルの画像が含まれている。
まずはじめは、dataフォルダ内にあるdog.jpgで画像認識、物体検出を行ってみよう。
これを実行する。
そうするとpreditions.jpgという画像ファイルがdarknetディレクトリの中にできているのがわかる。
predictions.jpgが解析結果の画像であることに注意。

以下の画像は公式のサイトのスクリーンショット。解析の様子と結果。

たとえば、自分が物体検出したい画像をcars.jpgとでもして、dataフォルダに入れれば、
$ ./darknet detect cfg/yolov3.cfg yolov3.weights data/cars.jpg
などとして使えばいい。検出結果の画像はpredictions.jpgになるので、上書きされる。
YOLOの初歩的応用:検出した物体を別画像として書き出す(Python,OpenCV)
画像を認識して、物体検出・物体検知できただけでも「お〜〜〜!」となるが、
大事なのは結局ここから向こう側だろう。
今回は検出した物体を別画像ファイルとして書き出すようにする。
実行してもらえれば分かる通り、
predictions.jpgで検出した物体の周りに線が引かれているだけだ。
この線がいったいどの範囲を囲っているのかわからない。
つまり、この線が囲っているX座標、Y座標、幅と高さの情報を抜き出せれば、画像を切り抜けるということだ。
それらの情報を知るためには、darknetフォルダの中にあるsrcフォルダのimage.cを編集する。
「えっ。。。C言語書くの???無理無理。。。」などと思わなくても、必要な箇所をコピペしたり、自分で応用する場合でも必要に応じて堅牢そうなC言語の書き方を真似すれば良いだけ。
image.cの292行目に以下のコードを追加してみよう。
前後の様子としてはこんな感じ。
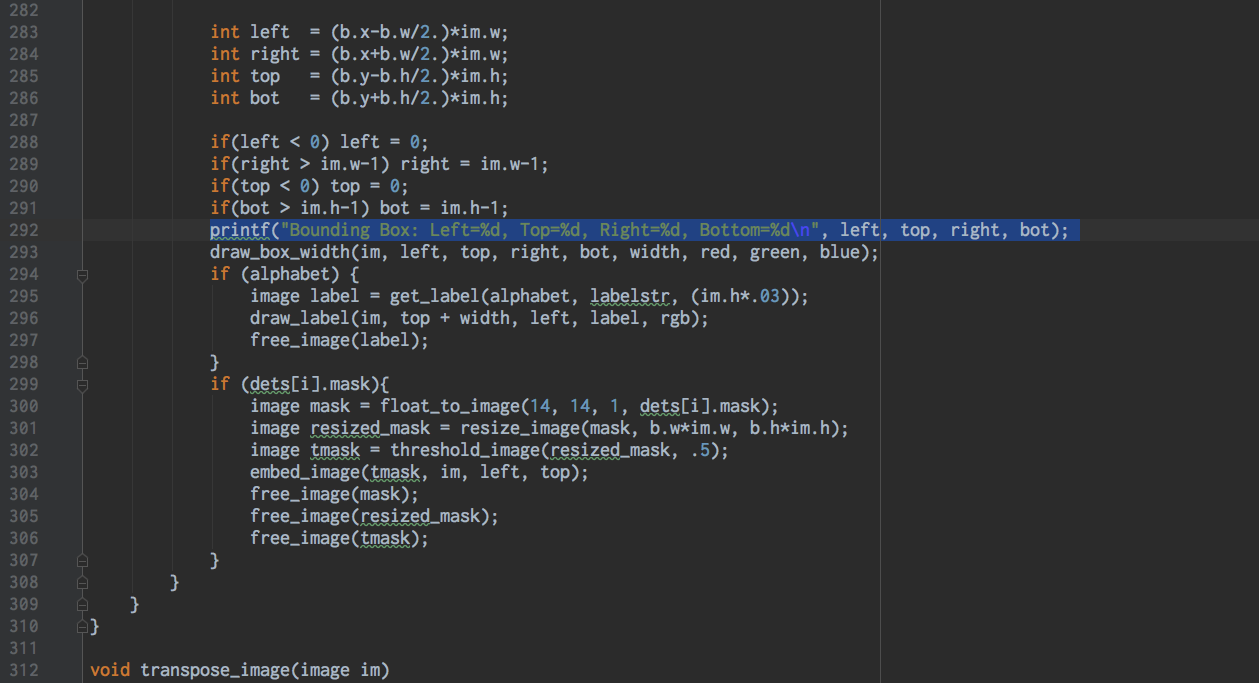
編集後のimage.cを保存した後に、makeコマンドでコンパイルし直すことが大事だ。忘れてはいけない。
image.cを編集して保存しただけでは適用されない。
さきほども出てきたが、以下のような感じでコンパイル。
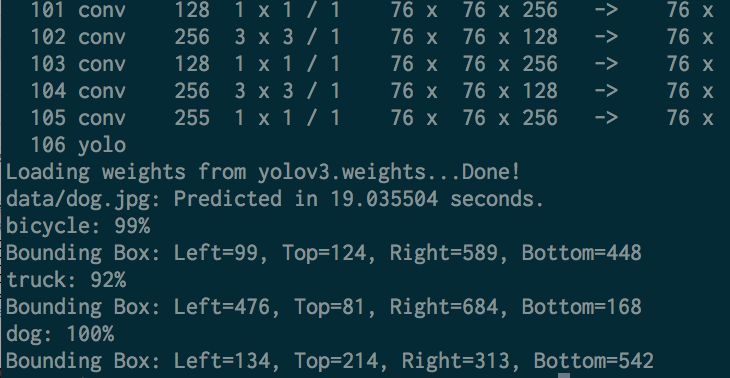
再び、犬・自転車・トラックが写っているdog.jpgで物体検出を実行。
下のように、範囲がprintされているのがわかっただろうか。
bicycle: 99%
Bounding Box: Left=99, Top=124, Right=589, Bottom=448
truck: 92%
Bounding Box: Left=476, Top=81, Right=684, Bottom=168
dog: 100%
Bounding Box: Left=134, Top=214, Right=313, Bottom=542
ターミナルでの様子は、
あとは、printされてきた数値をもとに、dog.jpgで犬だけを画像として書き出してみよう。
darknetフォルダにcut.pyと名付けたファイルを作成する。
|
1 2 3 4 5 6 7 8 |
import cv2 img = cv2.imread("data/dog.jpg") left, right = 134, 313 top, bottom = 214, 542 im2 = img[top:bottom, left:right] # 基礎的なことだが、書き方に注意 cv2.imwrite("only_dog.jpg", im2) |
$ python cut.py
のように実行すれば、犬だけが書き出されたonly_dog.jpgが生まれている。
im2 = img[top:bottom, left:right]の書き方には注意。縦が先。
できあがった画像は、
