Pandasのデータをさまざまなかたちで集計する関数が.agg()です。
groupby()で、グループを指定します。
|
1 2 |
import pandas as pd import numpy as np |
|
1 2 3 |
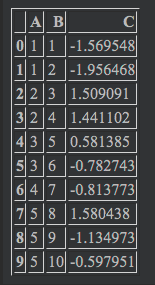
df = pd.DataFrame({'A': [1, 1, 2, 2, 3, 3, 4, 5, 5, 5], 'B': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10], 'C': np.random.randn(10)}) |
'A'では、1,2,3,5が複数存在し、4は1つしか存在していないところに注目してください。groupby()メソッドを'A'に適用した時、'A'における「かぶり」が除外されます。その様子をあとでお見せするために、あえて「かぶり」を存在させています。
'C'では、np.random.randn()という関数を用いています。randn()はガウス分布でランダムな数値を出力してくれます。
|
1 |
df |
|
1 |
df.groupby('A').agg('min') |
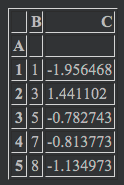
Aが1,2,3,4,5にグループ化されたことがわかります。
たとえば、Aが1の時、Bにおける最小値は1<2なので1。Cにおける最小値は-1.956468<-1.569548なので-1.956468のほうが表示されます。最小値は'min'と指定し、.agg('min')という書き方をしています。
|
1 |
df.groupby('A').agg(['min', 'max', 'sum']) |
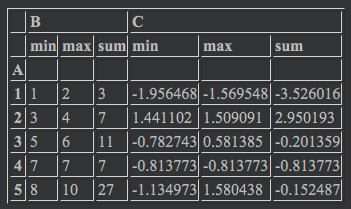
このように、表示したい数値を複数指定することができます。
|
1 |
df.groupby('A').C.agg(['min', 'max', 'sum', 'mean', 'median', 'std']) |
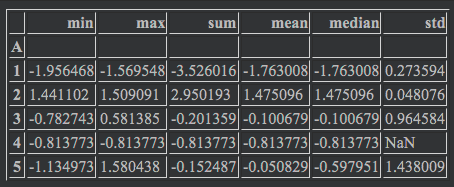
こちらの例では、Aでグルーピングして、Cの値を集計しています。.C.agg()となっており、Bが集計されていないことがわかります。
'min':最小値
'max':最大値
'mean':平均値
'median':中央値
'std':標準偏差
|
1 |
df.groupby('A').agg({'B': ['min', 'max'], 'C': 'sum'}) |
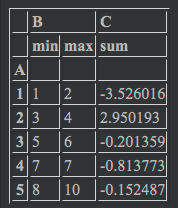
Aでグルーピングして、Bでは最小値と最大値、Cでは合計が見たい場合このように指定できます。