環境
macOS Sierra 10.12.6
ターミナル
Anaconda
Python 3.6.4
Anacondaをインストールすればデータサイエンスに必要なライブラリが使えるので、
ぜひインストールしましょう。
Anacondaのインストール手順についてはこちら
→MacにAnacondaをインストールする
matplotlibとは
データ可視化ツールのうちのひとつです。
データ分析を行う際に使います。
たった数行のPythonコードで簡単な棒グラフ、折れ線グラフ、散布図などを表示することができます。
matplotlib→https://matplotlib.org/
参考:matplotlibで日本語対応(文字化け解決),Mac
当記事で使うデータ
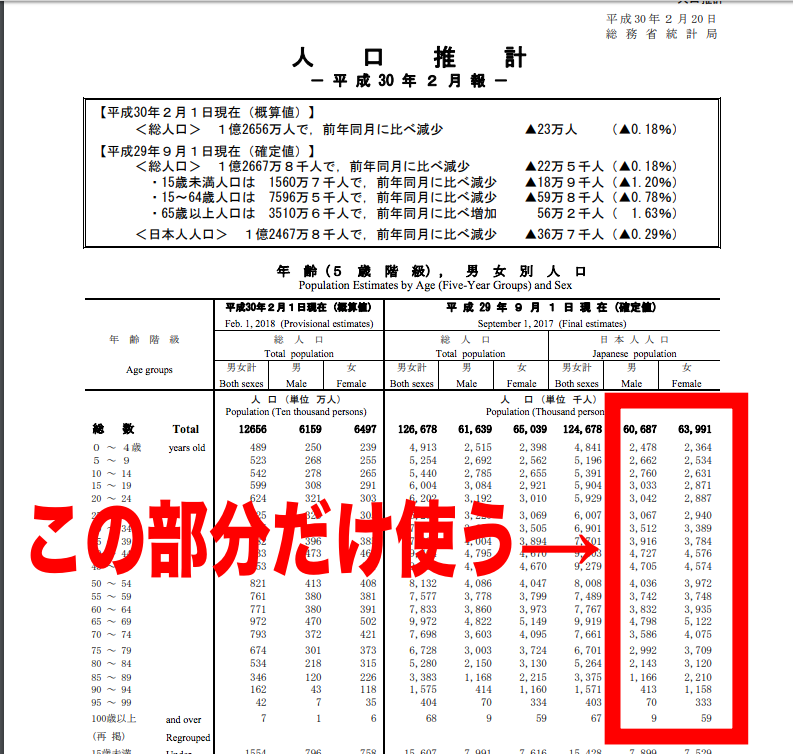
総務省統計局の人口推計のデータを参照します。
転載について記載するよう書いてあったので記載しておきます。
「人口推計」(総務省統計局)(http://www.stat.go.jp/data/jinsui/pdf/201802.pdf)(2018年3月7日に利用)
まず日本の男性の日本人人口を年齢別に見てみる
Anacondaがインストールされている前提で話を進めていきますね。
Anacondaではなくても、matplotlibが利用できる環境であれば大丈夫です!
さて、Pythonとmatplotlibで統計データを扱ってみようかと思い、
思いついたのが総務省統計局のデータでした。
その中でもポピュラーであろう、日本の人口に焦点を当ててみます。
人口推計と言うんですねぇ。
人口推計といっても様々な切り口があるので、
平成30年2月報の人口推計で、平成29年9月1日現在で日本人人口がどれだけいたのかの確定値を参考にしましょう。
下記の画像を参考にして下さい(人口推計のURLは→http://www.stat.go.jp/data/jinsui/pdf/201802.pdf)
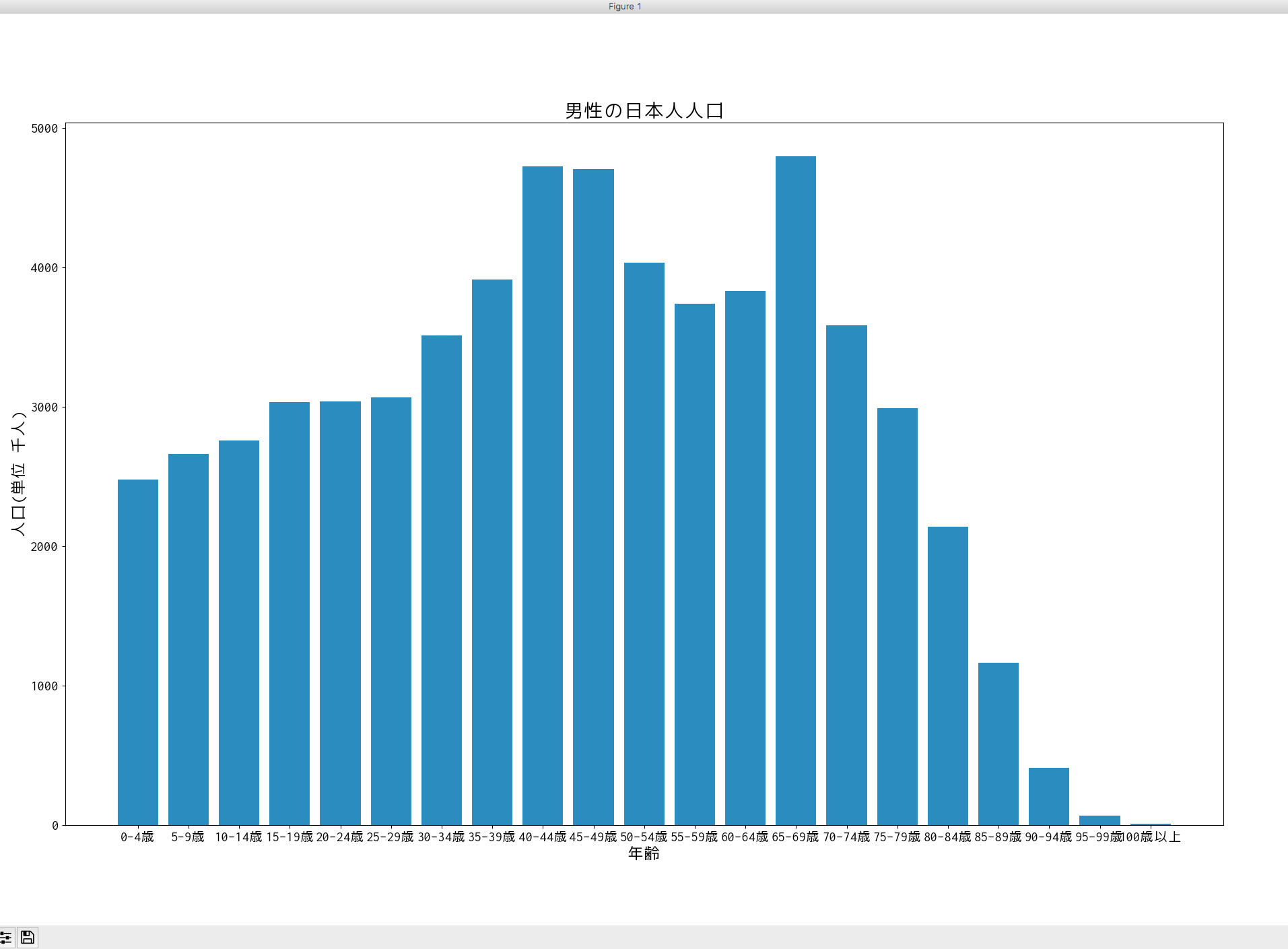
まずは男性の日本人人口を見てみましょう。
たとえば0歳から4歳の日本人の男性は2,478とあります。
単位は千人なので0を3つ加えることになり、2,478,000人で247万8000人ということですね。
結論から出すと、男性の日本人人口を棒グラフで表すと以下のようになりました。
Pythonの対話インタープリタでもいいですしIPythonでもなんでもいいのですが、
今回はPythonでそれなりの分量を書いていくということなので、
ちゃんとpyファイルを作って書きます。
Anacondaはインストールできていますか?

ファイルの名前はmale_ja_population.pyとします。
私はエディタはVimを使っているので、編集はこうなります。
![]()
実行の時は、
![]()
male_ja_population.pyにはどのように書いたかというと、
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
from matplotlib import pyplot as plt # フォントの選び方やサイズなどに関してはお好みでお願いします。 # 全体のフォントをRicty Diminishedにする。 plt.rcParams['font.family'] = 'Ricty Diminished' # フォントサイズを設定。「日本の男性の人口」「人口」「年齢」という文字の大きさ plt.rcParams['font.size'] = 18 # 横軸のフォントサイズ。たとえば「0-4歳」など plt.rcParams['xtick.labelsize'] = 15 # 縦軸のフォントサイズ。たとえば「1000」など plt.rcParams['ytick.labelsize'] = 15 # 人口推計でもそうしているように、年齢を5歳刻みで1セットとする。 # ageというリストで年齢要素を管理する。 age = ["0-4歳", "5-9歳", "10-14歳", "15-19歳", "20-24歳", "25-29歳", "30-34歳", "35-39歳", "40-44歳", "45-49歳", "50-54歳", "55-59歳", "60-64歳", "65-69歳", "70-74歳", "75-79歳", "80-84歳", "85-89歳", "90-94歳", "95-99歳", "100歳以上"] # 男性の日本人人口の値をpopulationというリストに格納。 # 単位が千人というのはそのまま採用、ageリストの順番と対応する。 # たとえば0-4歳は2478で、それぞれage[0],population[0]で対応しているということ。 population = [2478, 2662, 2760, 3033, 3042, 3067, 3512, 3916, 4727, 4705, 4036, 3742, 3832, 4798, 3586, 2992, 2143, 1166, 413, 70, 9] xs = [i + 0.5 for i, _ in enumerate(age)] # x軸はageの要素分だけ区切りあり ys = population # y軸の棒の高さはそのまま人口の数(単位は千人) plt.bar(xs, ys) # x軸をxs、y軸をysで棒グラフを作る plt.title("男性の日本人人口") # グラフのタイトル plt.xlabel("年齢") plt.ylabel("人口(単位 千人)") # x軸のラベルに年齢を棒の中心に配置 plt.xticks([i + 0.5 for i, _ in enumerate(age)], age) plt.show() |
ここでは、matplotlibの中でも、matplotlib.pyplotモジュールを使っています。
最初にフォントをRicty Diminishedに指定しています。
フォントや日本語関係についてはこちら→matplotlibで日本語対応(文字化け解決),Mac
年齢を格納したageリスト、人口の値を格納したpopulationリストを作っています。
x軸に関して、
というのが出てきてますね。
forの中に出てくる_(アンダーバー)やenumerate()関数がわからなければ、
こちらをどうぞ→enumerate関数でインデックスと要素を取得
簡単に言えば、ageリストのインデックスだけ取得しています。
大体コードの開設はコメントに書きました。
もし気になる点があればコピペして調べるきっかけにして頂ければと思います。
男性はどの年齢層が一番人口が多いのか求めてみよう
これはPythonの対話インタープリタでも求めることができます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
>>> age = ["0-4歳", "5-9歳", "10-14歳", "15-19歳", "20-24歳", "25-29歳", "30-34歳", ... "35-39歳", "40-44歳", "45-49歳", "50-54歳", "55-59歳", "60-64歳", ... "65-69歳", "70-74歳", "75-79歳", "80-84歳", "85-89歳", "90-94歳", ... "95-99歳", "100歳以上"] >>> population = [2478, 2662, 2760, 3033, 3042, 3067, 3512, 3916, 4727, 4705, ... 4036, 3742, 3832, 4798, 3586, 2992, 2143, 1166, 413, 70, 9] >>> max_population = max(population) # populationリストの最大値を求める >>> max_population 4798 # populationリストでは4798が一番大きな数字 >>> max_index = population.index(max_population) # 4798はリストの何番目なのか >>> max_index 13 # 4798という数字はpopulationリストの13番目にある >>> age[max_index] # ageリストのmax_index番目(13番目)にアクセス '65-69歳' |
結果:男性の日本人人口は65-69歳が一番多い
第2次世界大戦後の第一次ベビーブームの時に生まれた人が多いということですね。
団塊の世代などと呼ばれることもあります。
上のコードで使ったのはmax()とindex()ですね。
最大値を求めるのと、インデックスを取得しています。
max()とindex()についてはこちら→リスト・タプルの最大値,最小値,インデックスを求める
もしこの例のように比較する要素が少なければ、人間の目視でもどの年齢層が人口が多いのかわかります。
populationリストを見れば4798が一番大きくて、これをageリストと対照してみると65-69歳だなとなります。
しかし、これらが何万とか何十万とかの要素となってくると目視での確認は難しいですよね。
しかも、数字の大小の比較はコンピュータのお手の物で人間がやる必要のない作業です。
プログラミング化するというのは、人間の手ではなくコンピュータにやらせるところに意義があるのです。
女性の日本人人口を見てみる
男性ですでに利用したプログラムを利用できます。
populationリストの中身を変更し、グラフのタイトルを変えるだけです。
female_ja_population.pyという名前のファイルを作成しました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
from matplotlib import pyplot as plt # 全体のフォントをRicty Diminishedにする。 plt.rcParams['font.family'] = 'Ricty Diminished' # フォントサイズを設定。「日本の男性の人口」「人口」「年齢」という文字の大きさ plt.rcParams['font.size'] = 18 # 横軸のフォントサイズ。たとえば「0-4歳」など plt.rcParams['xtick.labelsize'] = 15 # 縦軸のフォントサイズ。たとえば「1000」など plt.rcParams['ytick.labelsize'] = 15 # 人口推計でもそうしているように、年齢を5歳刻みで1セットとする。 # ageというリストで年齢要素を管理する。 age = ["0-4歳", "5-9歳", "10-14歳", "15-19歳", "20-24歳", "25-29歳", "30-34歳", "35-39歳", "40-44歳", "45-49歳", "50-54歳", "55-59歳", "60-64歳", "65-69歳", "70-74歳", "75-79歳", "80-84歳", "85-89歳", "90-94歳", "95-99歳", "100歳以上"] # 女性の日本人人口の値をpopulationというリストに格納。 # 単位が千人というのはそのまま採用、ageリストの順番と対応する。 # たとえば0-4歳は2478で、それぞれage[0],population[0]で対応しているということ。 population = [2364, 2534, 2631, 2871, 2887, 2940, 3389, 3784, 4576, 4574, 3972, 3748, 3935, 5122, 4075, 3709, 3120, 2210, 1158, 333, 59] xs = [i + 0.5 for i, _ in enumerate(age)] # x軸はageの要素分だけ区切りあり ys = population # y軸の棒の高さはそのまま人口の数(単位は千人) plt.bar(xs, ys) # x軸をxs、y軸をysで棒グラフを作る plt.title("女性の日本人人口") # グラフのタイトル plt.xlabel("年齢") plt.ylabel("人口(単位 千人)") # x軸のラベルに年齢を棒の中心に配置 plt.xticks([i + 0.5 for i, _ in enumerate(age)], age) plt.show() |
実行します。
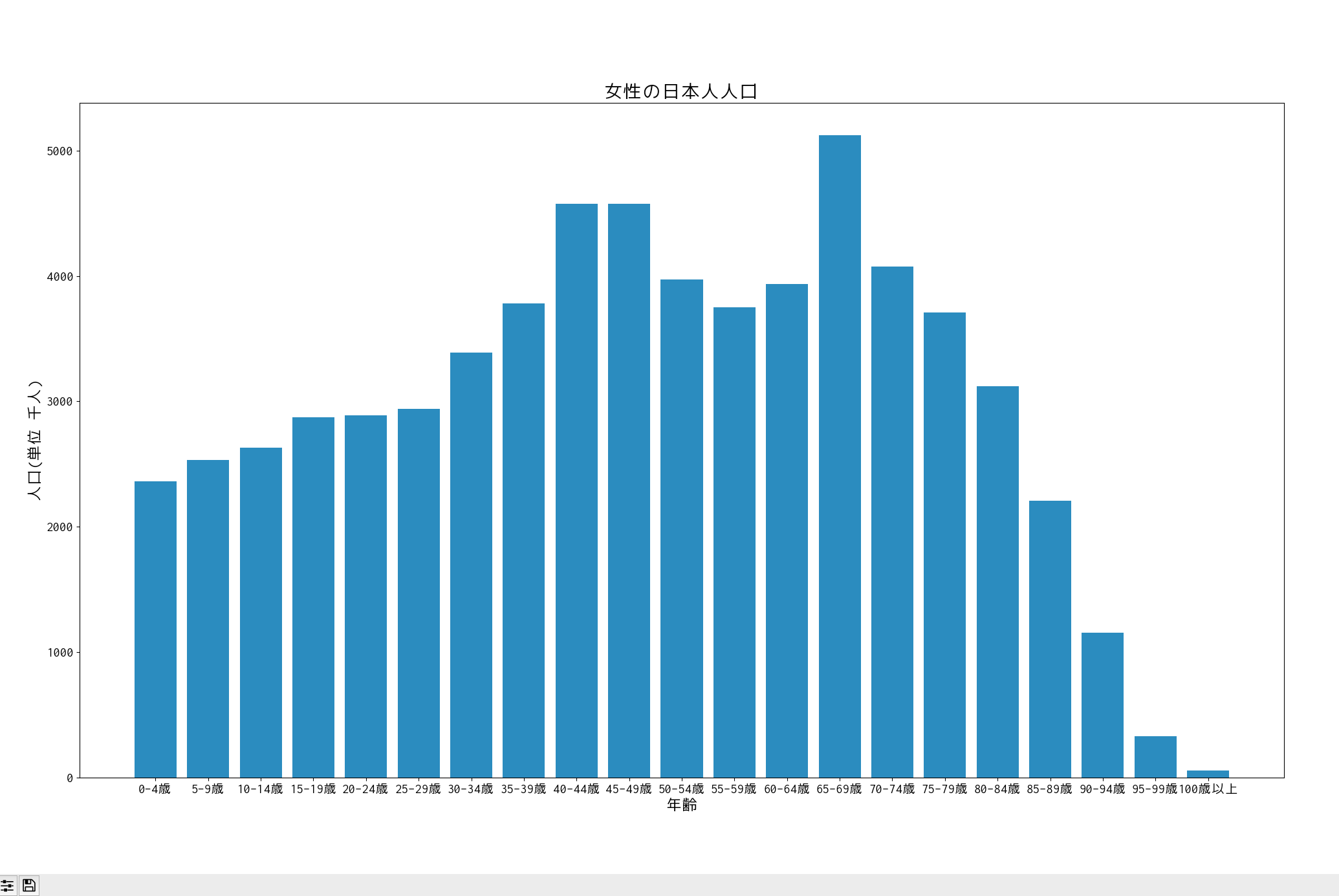
今回はここまで。
男性と女性のプログラムの違いは、populationリストの中身とタイトルだけでしたね。
つまり、コードのほとんどは共通部分。
次回ではクラス(class)の概念を用いて、コードの抽象化をしてみましょう。