最も基礎的な機械学習の例はXOR演算。
機械学習を使うまでもない、if文で十分に回答は得られる。
しかし、複雑過ぎるモデルをいきなり学んでもイメージが掴みずらいので、
XOR演算のようなものを利用する。
アヤメの品種分類よりも基礎的な内容だが、
XORは考えなしに解ける問題ではない。
Pythonで機械学習をするのにメジャーな「scikit-learn」を使用する。
scikit-learn(サイキットラーン)は機械学習の最重要ライブラリ
scikit-learnは「サイキットラーン」と読む。
scikit-learnはAnacondaをインストールすればついてくる。
Anacondaをインストールしていない人はこちら→MacにAnacondaをインストールする
2025年現在、Anacondaを使わずに「pipとvenv」だけでscikit-learnを導入・実行する方法も主流となっている。詳しくはこちらの記事を参照→Anaconda不要!pipとvenvでscikit-learn機械学習環境を作る
scikit-learnは無料で誰でも使うことができる。オープンソースプロジェクトなので、いつもどこかの天才たちが開発・改良してくれている。
機械学習においてscikit-learnはとても重要で、機械学習するためのいろいろなアルゴリズムが準備されている。機械が学習するための手法はたくさんある。データによって、選ぶべきアルゴリズムは異なるわけだが、scikit-learnを使えば手軽に多くのアルゴリズムを試すことができる。ある方法(アルゴリズム)では上手く学習できなかったのに、ある方法では上手くいくことがある。
scikit-learnの公式のユーザーガイドとAPIドキュメント
scikit-learn公式ユーザーガイド→http://scikit-learn.org/stable/user_guide.html
APIドキュメント→http://scikit-learn.org/stable/modules/classes.html
XOR(排他的論理和)とは? 機械学習の入門に最適な例題
XOR(排他的論理和)とは、二つの値のどちらかが真で、どちらかが偽の場合に真となるような性質を持つ。
| イケメン | 金持ち | 結婚 |
| 0(イケメンじゃない) | 0(貧乏) | 0(結婚しない) |
| 1(イケメン) | 0(貧乏) | 1(イケメンだから許す) |
| 0(イケメンじゃない) | 1(金持ち) | 1(金持ちだから許す) |
| 1(イケメン) | 1(金持ち) | 0(揃いすぎて怖い) |
| X | Y | Z |
どっちかがOKなら真だけど、両方ダメなのと両方OKなのは偽、という論理。
単純に一本の線で分類できない。
データと目的があってこその機械学習
たとえば上の例で言う。
あなたがもし結婚相談所で今までに100人と会ってみたとする。その100人の中で、あなたが「いい人だな」と思いデートまでいったのが20人だとする。ひどい話かもしれないが、デートに行く気にもなれなかった80人と会ったのは時間の無駄だったと考える。これから時間の無駄にならない人に効率的に出会うにはどうすればいいか。そこで機械学習を登場させ、分析をしてみるわけだ。
今までに会った人の中でイイなと思わなかった人は、金もなくて顔もイマイチ、もしくは金も顔も良すぎて自分には無理な人間だったとする。顔が気に入っているか、金持ちであれば安心して関係を進めていける。
まとめると、
データ:今までに出会った人
目的:より効率的に結婚相手を探す
scikit-learnで実装
K最近傍法
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
from sklearn.neighbors import KNeighborsClassifier # K最近傍法を使うためのクラスをscikit-learnからインポート from sklearn.metrics import accuracy_score # 正解率(予測精度)を計算する関数 # 学習用のデータと結果を準備する learn_data = [[0, 0], [1, 0], [0, 1], [1, 1]] learn_label = [0, 1, 1, 0] # アルゴリズムを指定。K最近傍法を採用(n_neighborsは最も近いデータをいくつ見るか) clf = KNeighborsClassifier(n_neighbors=1) # 学習用データのパターンをモデルに覚えさせる(fit) clf.fit(learn_data, learn_label) # fitは「データの特徴」と「結果」の関係を覚える作業 # 覚えた知識を使って未知データの結果を予測(predict) test_data = [[0, 0], [1, 0], [0, 1], [1, 1]] test_label = clf.predict(test_data) # predictはfitで覚えた知識から答えを出す作業 # 予測結果を評価する(accuracy_score) print("予測対象:", test_data, ", 予測結果→", test_label) print("正解率=", accuracy_score([0, 1, 1, 0], test_label)) |
- KNeighborsClassifier:scikit-learnが提供する近傍法(近くのデータを見て分類する)のアルゴリズム。
- fit():データと正解をもとに特徴やパターンを学習する(覚える)。
- predict():覚えたパターンを使って新しいデータに対して結果を予測する。
上記のコードは機械学習基礎において最もシンプルなコードのうちの一つだろう。
learn_dataが学習すべきデータ、learn_labelがその結果(答え)である。
言い換えれば、learn_dataがイケメンかどうか、金持ちかどうかを示している。learn_labelは結婚するかしないかを示している。
今回は分類問題、結婚するorしない、というシンプルなもの。
分類問題を解くにも様々なアルゴリズムがあるが、今回はKNeighborsClassifier(K最近傍法)を採用。n_neighborsは近傍点を何個にするかという設定。今回は1個。学習用データに含まれる点の中で、予測したいデータに最も近いものを見る。
このアルゴリズムはどうやって選んだのか。自分が解く問題にはどのアルゴリズムを採用すればいいのか。
それは下記のscikit-learnのアルゴリズムチートシートを参照。
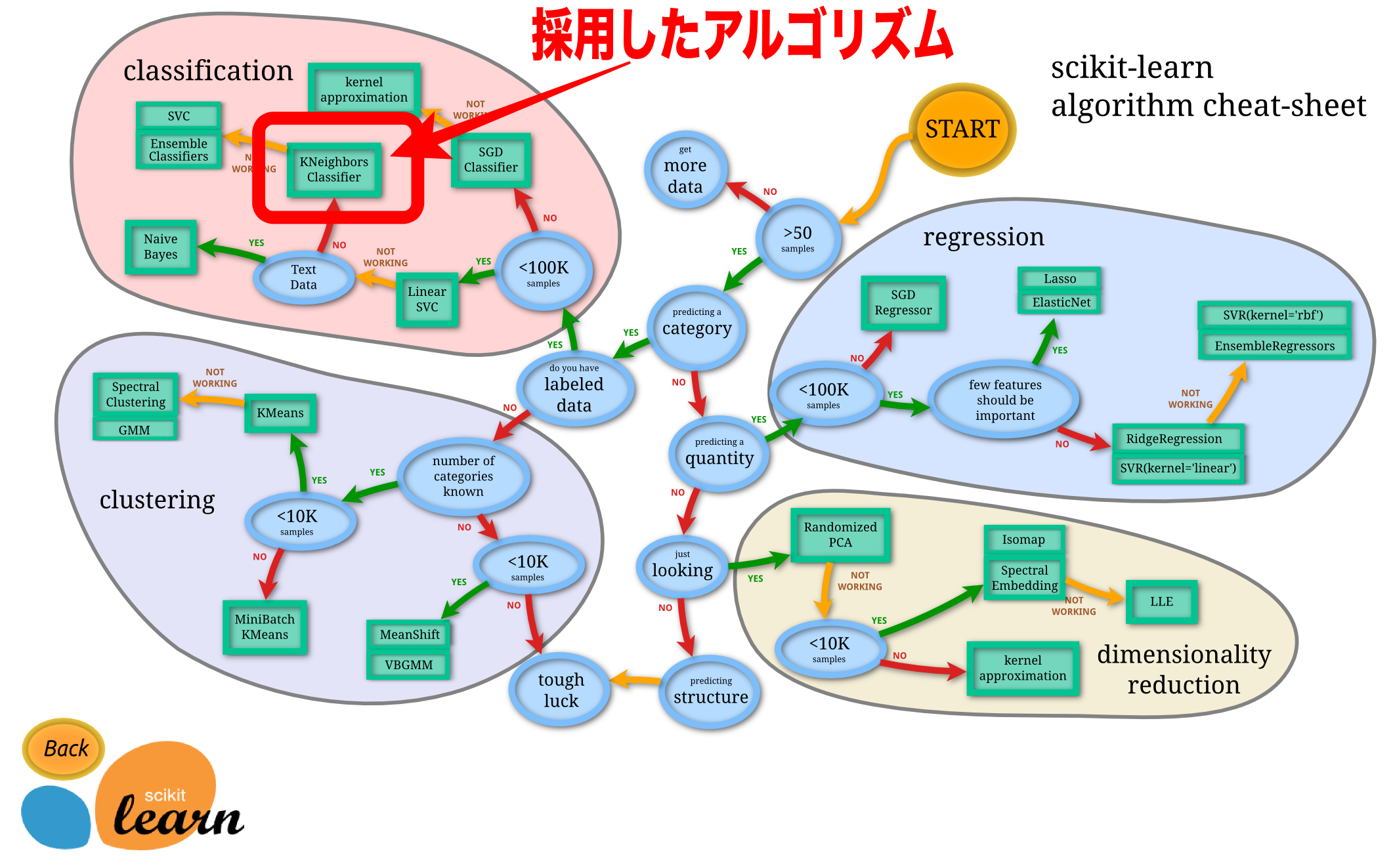
この画像はhttp://scikit-learn.org/stable/tutorial/machine_learning_map/index.htmlより引用させてもらい、矢印や文字を付け加えさせてもらった。
clf.fit(learn_data, learn_label)という部分で、KNeighborsClassifierに基づき学習する。fit()と書くだけで学習できるのはすごいことだ。
この段階で機械学習は完了しているが、機械学習にとって大事なのはデータが与えられた時に予測ができ、その予測精度が高いことである。
predict()で予測し、accuracy_scoreで予測精度を出している。実行すると、以下のようにでる。
予測対象: [[0, 0], [1, 0], [0, 1], [1, 1]]
予測結果→ [0 1 1 0]
正解率= 1.0(100%)
予測対象に対して、正確な予測結果が出ている。正解率は1.0、すなわち100%だ。
アルゴリズムを変えてみる。SVM(サポートベクターマシン)
アルゴリズムを簡単に変えることができるのがscikit-learnの大きな特徴だ。
試しにサポートベクターマシン(support vector machine:SVM)を使ってみる。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
from sklearn import svm # サポートベクターマシン(SVM)を使うためのクラスをscikit-learnからインポート from sklearn.metrics import accuracy_score # 正解率(予測精度)を計算する関数 # 学習用のデータと結果を準備する learn_data = [[0, 0], [1, 0], [0, 1], [1, 1]] learn_label = [0, 1, 1, 0] # アルゴリズムを指定。SVM(サポートベクターマシン)を採用 clf = svm.SVC() # 学習用データのパターンをモデルに覚えさせる(fit) clf.fit(learn_data, learn_label) # fitは「データの特徴」と「結果」の関係を覚える作業 # 覚えた知識を使って未知データの結果を予測(predict) test_data = [[0, 0], [1, 0], [0, 1], [1, 1]] test_label = clf.predict(test_data) # predictはfitで覚えた知識から答えを出す作業 # 予測結果を評価する(accuracy_score) print("予測対象:", test_data, ", 予測結果→", test_label) print("正解率=", accuracy_score([0, 1, 1, 0], test_label)) |
- SVM(Support Vector Machine):分類や回帰問題に広く使われる、データ間に境界線を引いて分類するアルゴリズム。
- svm.SVC():SVMの分類問題向けのクラス。
- fit():学習用データのパターンを覚える。
- predict():覚えたパターンをもとに、新しいデータの結果を予測する。
変更したのはたったの2箇所。
SVMをインポートする冒頭の部分と、アルゴリズムの指定のところだけ。
結果はK最近傍法と同じになる。
scikit-learnまとめ(機械学習の基本の流れ)
機械学習を行うためには、以下の手順を繰り返して精度を高めていく。
- データを準備する:機械学習の元となるデータを集め、分析や分類ができる形に整える(前処理)。
- アルゴリズムを選ぶ:解きたい問題に適したアルゴリズムを選択(例:K最近傍法、SVMなど)。迷ったらscikit-learnのチートシートを参考にする。
- 学習する(fit):用意したデータと答え(ラベル)をアルゴリズムに渡してパターンを覚えさせる。
- 予測する(predict):学習したモデルを使って未知のデータを分類または予測する。
- 精度を評価する(accuracy):予測結果の精度を評価し、満足のいく結果が得られるまでアルゴリズムやパラメータを調整する。
scikit-learnは、この一連の流れをシンプルかつ簡単に実行できるライブラリである。豊富なアルゴリズムや便利な評価ツールがそろっているので、初心者でも手軽に機械学習を始められる。scikit-learnをまだ使ったことがない方はこちらの記事から(2025年6月更新)→Anaconda不要!pipとvenvでscikit-learn機械学習環境を作る